
De fleste danske offentlige myndigheder og virksomheder er allerede meget langt fremme, i forhold til at sikre dataintegration og har flere års erfaring med digital sagsbehandling og dermed lagring af afgørelser og sagsdata. Så nu kan næste generation af IT-systemer anvende dette til at lære rutiner og regler, som kan understøtte sagsbehandlernes beslutningsproces, eller helt automatisere dele af den.
Helt enkelt, så handler en sagsgang om at samle tilstrækkeligt information igennem en proces, med det formål at kunne træffe en begrundet afgørelse på en sag. Der er selvfølgelig mange variable, der påvirker sagsbehandlingen og hvordan en afgørelse træffes, men følgende er fælles i bestræbelsen for at skabe fremskridt i sagsgangene.
Man skal:
- Delegere sagen hen til den eller de ressourcer, som på kortest mulig tid kan belyse sagen nok til at en afgørelse kan træffes, eller at den kan gå videre til næste kritiske led i processen.
- Sikre korrekt og velbegrundet dokumentation for afgørelser og beslutninger i sagen.
- Overholde reguleringer, lovgivning og tidsfrister for sagsbehandlingsprocessen.
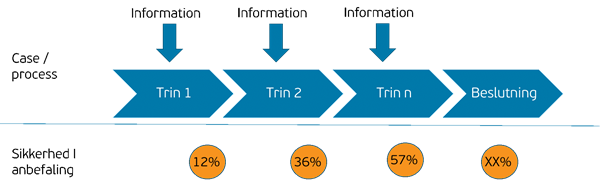
Nedenstående figur illustrerer princippet i et sagsforløb. Igennem processen bliver der samlet information og til sidst træffes en afgørelse. Det er så at sige informationsflowet, der driver fremdriften af sagsforløbet. Et beslutningsanbefalingssystem kan regne på denne information sammenholdt med de historiske data og give en anbefaling til en afgørelse. Jo mere information der tilføjes processen, des større er sikkerheden i den anbefalede afgørelse. Det er derfor vi med Big Data-teknologier nu har mulighed for realistisk at hjælpe med sagsafgørelserne.
En case til illustration af potentialet
En offentlig styrelse modtager årligt over en million ansøgninger fra borgere, som gennemgår en manuel proces, hvor der samles information fra forskellige kilder, med det formål at godkende eller afvise ansøgningerne. Styrelsen har flere års information og historik om afgørelser fra 9 forskellige datakilder. Langt de fleste ansøgninger (95%) resulterer i en godkendt ansøgning.
Ved at sammenholde en stor pulje af de historiske data med de dertil hørende afgørelser, lavede vi en beregning af alle sammenhænge i data. Dette resulterede i en model og et regelsæt som vi testede op imod et nyere datasæt og afgørelser. Testresultatet viste, at den datadrevne beslutningsanbefaling i 72 pct. af tilfældene anbefalede en straks godkendelse og, at denne anbefaling kun var fejlbehæftet med 1 pct. Afgørelser blev også truffet på data som ikke bliver opsamlet i styrelsen. Hvis styrelsen får adgang til disse data kan modellen og dermed business casen styrkes yderligere.
Businesscasen viser at der er et potentiale til at spare over 120 mio. kr. årligt på at lave straksafgørelser baseret på Big Data. Det er ca. halvdelen af de administrative omkostninger direkte forbundet med sagsbehandlingen.
Det tog ca. 2 måneder at gennemføre foranalysen.
Sagsbehandlingens IT-understøttelse
IT er blevet et uundværligt redskab til at understøtte sagsbehandling, idet mængden af tilgængelig digital information er enorm og stærkt stigende.
Traditionelt set understøtter IT et sagsforløb ved at:
- Validere og sikre at data fra sagsgrundlaget (ansøgning) er tilstrækkeligt til, at det videre sagsforløb kan gå i gang med mindst muligt tilbageløb.
- Samle dokumentation af sagens dokumenter, detaljer og metadata.
- Integrere til eksterne datakilder og dermed hjemhente information, der skal understøtte beslutninger i sagen.
- Sikre dokumentation og regler, der kan hjælpe med at træffe afgørelser.
- Give overblik til sagsbehandlere og ledere om sagens indhold og fremskridt.
- Have beregningskerner der kan udregne udbetalinger og omkostninger ved sagens afgørelser.
- Producere ledelsesinformation om sagernes fremdrift.
Man kan understøtte denne sagsgang med Big Data med kraftige produktivitetsforbedringer til følge. En datadrevet tilgang til denne opgave kunne eksempelvis være via superviseret Machine Learning, hvor man ud fra historiske data lærer computeren, hvordan udfaldet i en lang række forskellige afgørelser har været. Systemet lærer og opbygger en model via disse data, som derefter kan anvendes på nye sager. Ud fra sagens indhold og modellen, kan den foreslå hvilken afgørelse, der sandsynligvis er den korrekte og endda med hvor høj sandsynlighed. Dette svarer lidt til en form for datasans, der ”sanser” data og dermed bestemmer, hvilken kasse en given sag skal placeres i.
Datadrevet beslutningsstøtte kan anvendes i alle de områder, hvor der er rige datakilder og komplicerede beslutningsprocesser. Afhængigt af datakilderne kan anvendelse f.eks. være:
- Straksgodkendelser
- Det optimale næste skridt i en proces
- Simulering af forskellige udfaldsrum i processen
- Identifikation af regler
Hvordan kommer man i gang
Det kræver ikke de store investeringer at starte med datadrevet beslutningsunderstøttelse. Indledningsvist handler det om at identificere den rette business case, teste processen og planlægge et roadmap for at implementere, måle og gradvist forbedre modellen. Vi har erfaret, at der er en tæt forbindelse mellem investeringens størrelse og effektiviseringspotentialet. Selv mindre virksomheder kan høste store gevinster ved datadrevet beslutningsunderstøttelse.
Potentialet i business casen vurderes af hvor mange sager der er i en given proces samt, hvor meget den manuelle sagsbehandling koster i tid, ressourcer og kundetilfredshed.
Der er tre afgørende faktorer der er bestemmende for hvilken løsning og infrastruktur der skal investeres i:
1. Dækningsgraden af data som understøtter historiske beslutninger.
2. Risikoen eller omkostningen ved at tage fejl.
3. Mængden, volumen eller diversiteten af data der indgår i analysen (Big Data).
Dækningsgraden af tidligere afgørelser vil være mere eller mindre dækket af relevant data. Ofte vil der være sager, hvor afgørelsen delvist er truffet ud fra opslag i 3. parts systemer, og dermed vil dokumentationen ikke være tilgængelig. Det påvirker sandsynligheden for hvor nøjagtig en afgørelse er og dermed øges risikoen og omkostningen ved at basere beslutninger på datadrevne afgørelser. Her vil det kræve, at der investeres i at få adgang til datakilderne, enten ved ekstern integration, eller ved at sikre at dokumentationen hentes hjem under sagsbehandlingen.
Risikoen i den enkelte sag har naturligvis en meget afgørende rolle. En beslutning der påvirker et helbredsmæssigt udfald, eller har en meget høj omkostning i sig selv, kræver selvfølgelig mere omfattende ressourcer at løse, og dermed også en mere kompliceret model.
Mængden, volumen eller diversiteten af data der indgår i analysen er også afgørende for tilgangen, idet det påvirker maskinkraften, der skal anvendes til at lave beregninger. Den enkelte sags tyngde (afgørelsens påvirkning på fremtidige beslutninger) er ligeledes et udtryk for en kompleksitet, der skal håndteres af systemet. Det vil kræve flere realtidsorienterede beregninger jo større indflydelse den enkelte sag har på fremtidige afgørelser. Dette har indflydelse på den bagvedliggende infrastruktur der skal investeres i.
Vi har erfaret at man kan nå langt med den eksisterende infrastruktur der findes i de fleste danske virksomheder. Investering i Big Data teknologi såsom Hadoop er først nødvendig ved gigantisk store datamængder, som de færreste virksomheder endnu har akkumuleret. Derfor er investeringen enten ikke nødvendig, eller den kan udskydes til når virksomheden har fået erfaringer og har realiseret en business case, der viser et endnu større potentiale.
Vi anbefaler følgende tilgang til at komme i gang med datadrevet beslutningsunderstøttelse:
1. Start med at lave en business case, og hvis det er muligt understøt business casen med data fra et proof of concept på en af jeres processer. Kortlæg potentielle processer i virksomheden – afklar det eksisterende datagrundlag og beregn potentialet. Business casen bør også indeholde en investeringsplan eller et roadmap, der viser investeringer, samt de forventede realiserede effekter over tid.
2. Næste skridt er et pilotprojekt, der har til formål at give erfaringer med datadrevne beslutninger og måle effekten på faktiske forretningsscenarier.
3. Indfør relevante kontrolmekanismer såsom stikprøver.
4. Foretag iterative forbedringer af modellen ved at tilføje mere data til processen på den måde forbedres business casen.


